Method Overview
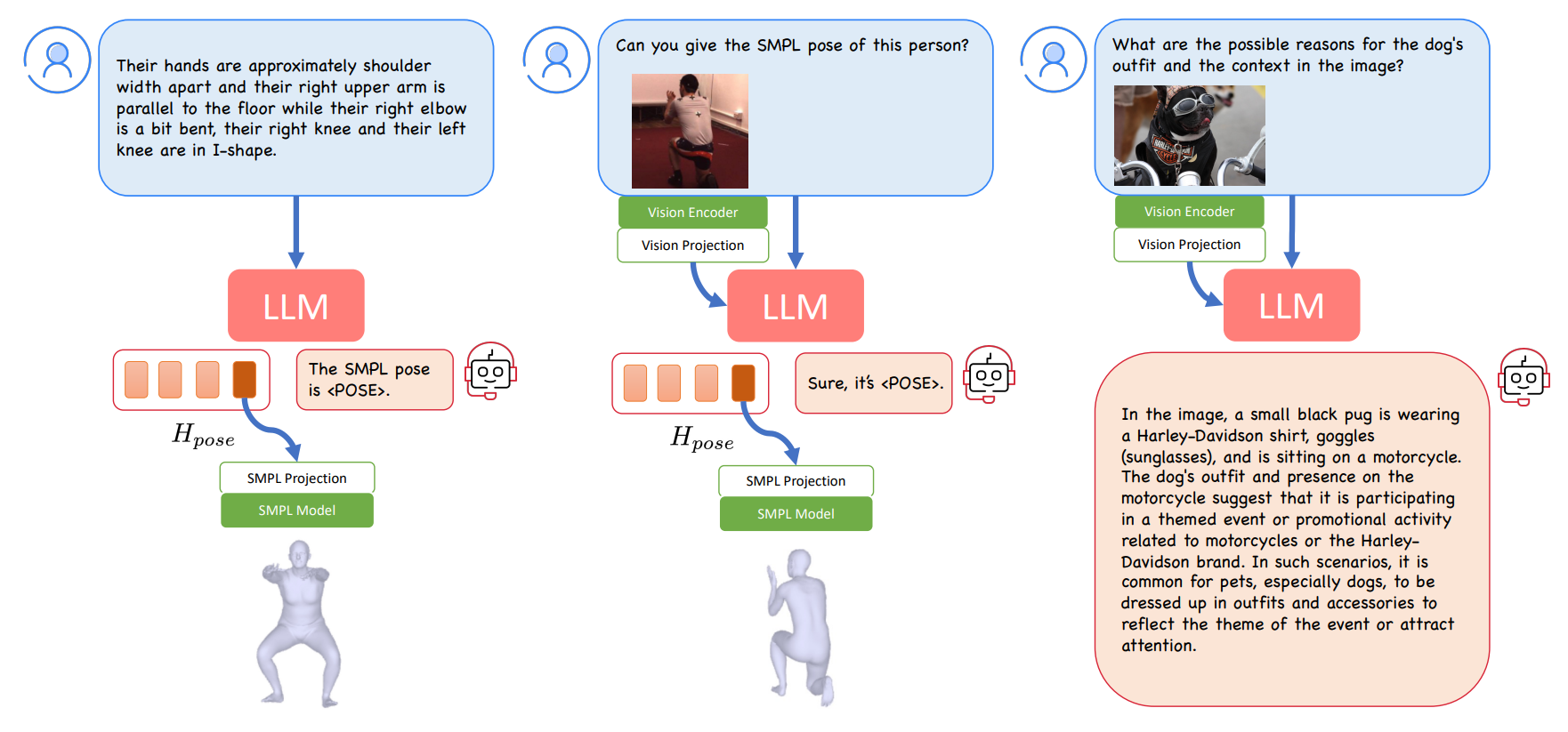
Our model is composed of a multi-modal LLM (with vision encoder, vision projection layer and LLM), a SMPL projection layer, and the parametric human body model, i.e. SMPL. The multi-modal LLM processes text and image inputs (if provided) to generate textual responses. In the training phase, we focus on training the SMPL projection layer and fine-tuning the LLM, while keeping the other components frozen. The three data types used for the end-to-end training are: text-to-3D pose generation, image-to-pose estimation, and multi-modal instruction-following data. When an image is available, its information is used by the LLM to deduce an answer. If the user inquires about a SMPL pose, the LLM responds with a
Results

Examples for Speculative Pose Genereation (SPG). The query examples are sourced from our SPG benchmark, which offers implicit text queries regarding human poses. GPT-4 (with DALL·E 2) generates images that depict the correct pose but does not explictly generate 3D poses. In contrast, PoseScript is a task-specific method for 3D pose from language but it is not able to relate high-level concepts like ``searching under furniture" with 3D pose. Our method ChatPose, understands high-level concepts and how to relate them to 3D pose.
Examples for Reasoning-based Pose Estimation (RPE). The queries are from our RPE benchmark, which offers different types of text descriptions of the target person. Comparison with LLaVA and classical HMR-style methods HMR2.0 and SPIN on RPE. LLaVA-S refers to the process of using LLaVA for keypoint detection, followed by SMPL pose optimization via SMPLify. LLaVA-P uses LLaVA to obtain textual descriptions of the pose, which are then input into PoseScript to generate human poses. For each method, we utilize the entire image provided by the user as input, without applying cropping. Methods involving LLMs are highlighted in orange, while those that are purely task-specific methods, are marked in green.
We provide the benchmark annotations here.
Acknowledgements
We thank Weiyang Liu, Haiwen Feng and Longhui Yu for discussions and proofreading.
We also thank Naureen Mahmood and Nicolas Keller for support with data.
This work was partially supported by the Max Planck ETH Center for Learning Systems.
Disclosure.
MJB has received research gift funds from Adobe, Intel, Nvidia, Meta/Facebook, and Amazon. MJB has financial interests in Amazon and Meshcapade GmbH. While MJB is a co-founder and Chief Scientist at Meshcapade, his research in this project was performed solely at, and funded solely by, the Max Planck Society.
Related Links
Note: The original name of ChatPose, 'PoseGPT,' was changed to avoid confusion with similarly named previous works
For more related works, please check out the following links:
Third wave 3D human pose and shape estimation A blog about the development of 3D human pose and shape estimation.
PoseScript for 3D human pose generation from text.
HMR,SPIN,HMR2 for 3D human pose and shape estimation from images.
BibTeX
@InProceedings{feng2024chatpose,
author = {Feng, Yao and Lin, Jing and Dwivedi, Sai Kumar and Sun, Yu and Patel, Priyanka and Black, Michael J.},
title = {ChatPose: Chatting about 3D Human Pose},
booktitle = {CVPR},
year = {2024}
}