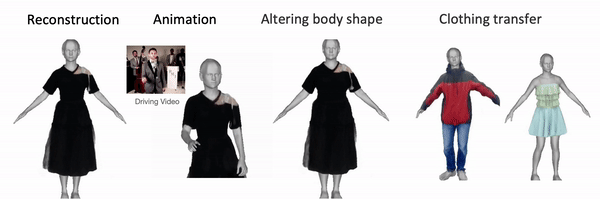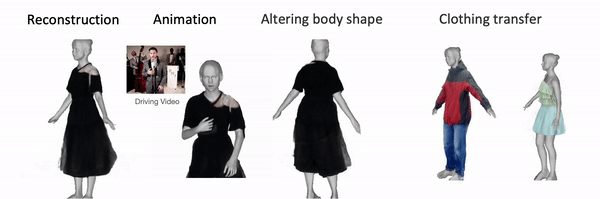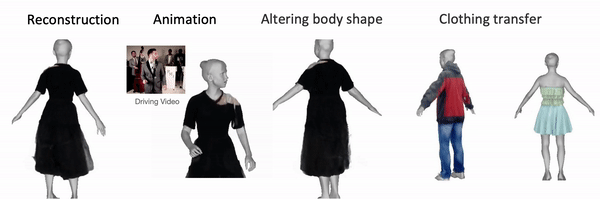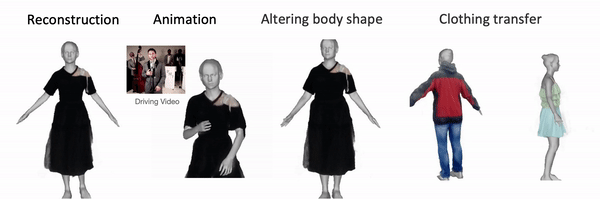
We thank Sergey Prokudin, Weiyang Liu, Yuliang Xiu, Songyou
Peng, Qianli Ma for fruitful discussions, and Peter Kulits, Zhen
Liu, Yandong Wen, Hongwei Yi, Xu Chen, Soubhik Sanyal, Omri
Ben-Dov, Shashank Tripathi for proofreading.
We also thank Betty Mohler, Sarah Danes, Natalia Marciniak, Tsvetelina Alexiadis, Claudia Gallatz, and Andres Camilo Mendoza Patino for their supports
with data. This work was partially supported by the Max Planck
ETH Center for Learning Systems.
Disclosure. MJB has received research gift funds from Adobe, Intel, Nvidia, Meta/Facebook, and Amazon. MJB has financial interests in Amazon, Datagen Technologies, and Meshcapade GmbH. While MJB is a part-time employee of Meshcapade, his research was performed solely at, and funded solely by, the Max Planck Society.
While TB is part-time employee of Amazon, this research was performed
solely at, and funded solely by, MPI.