|
Yao Feng I'm a Postdoc at Stanford, working with Karen Liu, Jennifer Hicks, and Scott L. Delp. I received my PhD from ETH Zürich and Max Planck Insistitute Intelligence Systems under the supervision of Michael J. Black and Marc Pollefeys. I also worked as a research scientist at Meshcapade for one year. My research focuses on capturing and understanding digital humans at scale, with applications across multiple disciplines, including computer vision, computer graphics, biomechanics, and robotics. |

|
News |
|
Mar 2026 Meshcapade, where I previously worked as a Research Scientist, has been acquired by Epic Games! Nov 2025 Give a talk at the University of Michigan. Sep 2025 Give a talk at Stanford SVL. June 2025 Give a talk at CVPR 2025 Workshop. June 2025 Co-organize CVPR 2025 Workshops: 3DHuman (A 2025 Perspective on 3D Human Perception, Reconstruction, and Synthesis) and Scene Understanding (5th 3D Scene Understanding for Vision, Graphics, and Robotics). May 2025 Received Eurographics PhD Award Honorable Mention. Oct 2024 Passed my PhD thesis defense: Learning Digital Humans from Vision and Language. Oct 2024 Selected as MIT Rising Stars in EECS. Sep 2024 Organize ECCV 2024 Workshop, Foundation Models for 3D Humans. Jul 2024 Selected as WiGRAPH Rising Stars in Computer Graphics. |
ResearchMy ultimate goal is to build digital humans that reflect who we are: how we look, how we move, and how we think, whether in virtual worlds or embodied in robots. To achieve this, I build scalable models that learn directly from everyday vision and language, enabling lifelike bodies and intelligent behaviors. Ultimately, I hope to shape a future where AI understands and interacts with the world, and with people, as naturally as we do.
Human Foundation Model
|
Publications(show selected / show all by date) |
|
|
GentleHumanoid: Learning Upper-body Compliance for Contact-rich Human and Object Interaction
Qingzhou Lu*, Yao Feng*, Baiyu Shi, Michael Piseno, Zhenan Bao, C. Karen Liu arXiv, 2025 project page / arXiv / code |
|
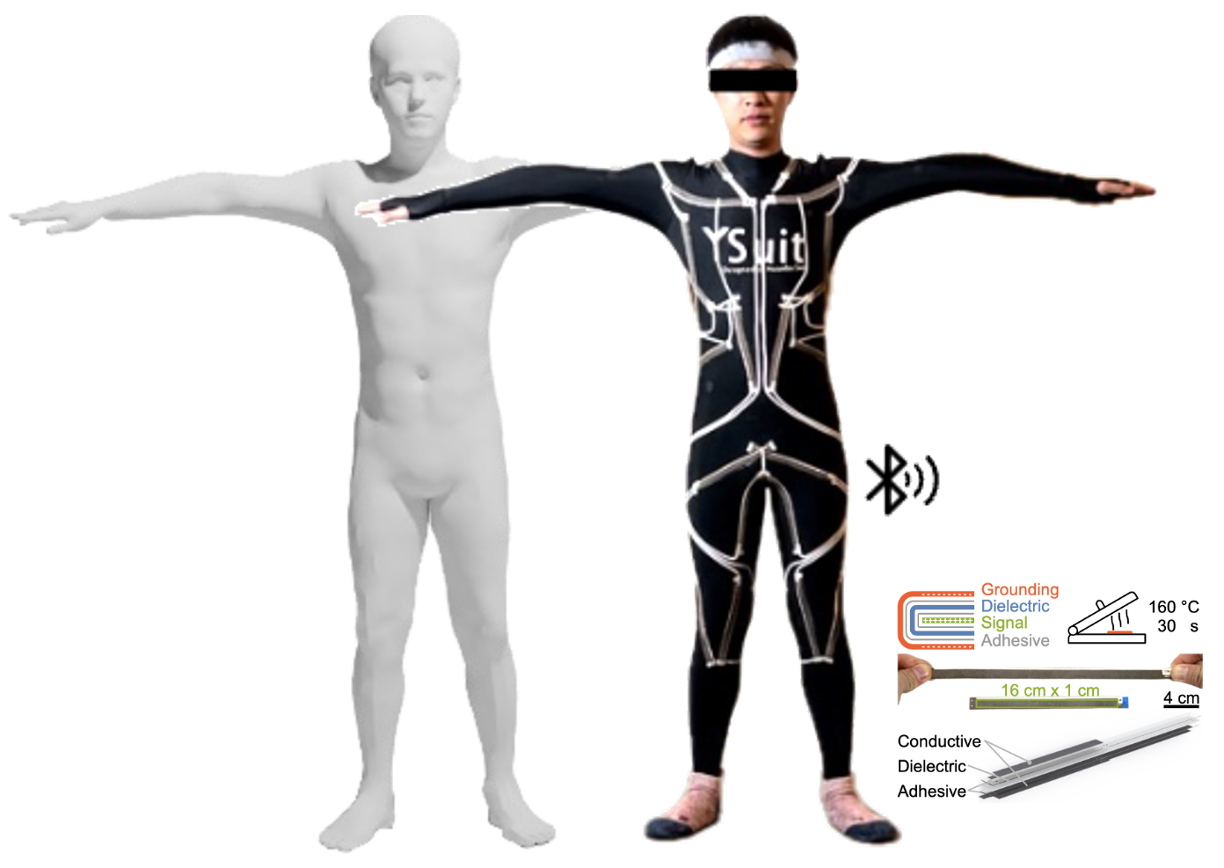
Textile suit for anywhere full-body motion capture
Huanbo Sun, Yao Feng, Pei-Chun Kao, Michael J. Black, Rebecca Kramer-Bottiglio Science Advances, 2026 |
|
|
PRIMAL: Physically Reactive and Interactive Motor Model for Avatar Learning
Yan Zhang, Yao Feng, Alpár Cseke, Nitin Saini, Nathan Bajandas, Nicolas Heron, Michael J. Black ICCV, 2025 project page / arXiv / code |
|
|
HaPTIC: Predicting 4D Hand Trajectory from Monocular Videos
Yufei Ye, Yao Feng, Omid Taheri, Haiwen Feng, Shubham Tulsiani*, Michael J. Black* arXiv, 2025 project page / arXiv / code |
|
|
ChatHuman: Chatting about 3D Humans with Tools
Jing Lin*, Yao Feng*, Weiyang Liu, Michael J. Black CVPR, 2025 project page / arXiv |
|
|
ChatGarment: Garment Estimation, Generation and Editing via Large Language Models
Siyuan Bian, Chenghao Xu, Yuliang Xiu, Artur Grigorev, Zhen Liu, Cewu Lu, Michael J. Black, Yao Feng CVPR, 2025 project page / arXiv / code |
|
|
DiffLocks: Generating 3D Hair from a Single Image using Diffusion Models
Radu Alexandru Rosu*, Keyu Wu*, Yao Feng, Youyi Zheng Michael J. Black CVPR, 2025 project page / arXiv / code |
|
|
ChatPose: Chatting about 3D Human Pose
Yao Feng, Jing Lin, Sai Kumar Dwivedi, Yu Sun, Priyanka Patel, Michael J. Black CVPR, 2024 project page / arXiv / code |
|
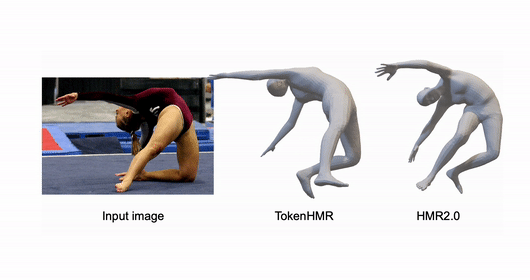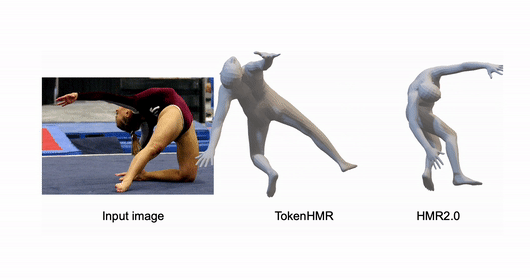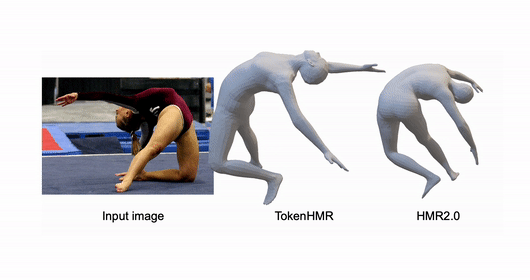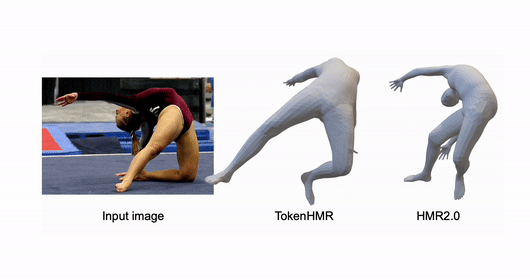
TokenHMR: Advancing Human Mesh Recovery with a Tokenized Pose Representation
Sai Kumar Dwivedi*, Yu Sun*, Priyanka Patel, Yao Feng, Michael J. Black CVPR, 2024 project page / paper / code
|
|
|
MonoHair: High-Fidelity Hair Modeling from a Monocular Video
Keyu Wu, Lingchen Yang, Zhiyi Kuang, Yao Feng, Xutao Han, Yuefan Shen, Hongbo Fu, Kun Zhou, Youyi Zheng CVPR, 2024 project page / arXiv / code
|
|
|
Ghost on the Shell: An Expressive Representation of General 3D Shapes
Zhen Liu, Yao Feng*, Yuliang Xiu*, Weiyang Liu, Liam Paull, Michael J. Black, Bernhard Schölkopf ICLR, 2024 project page / arXiv / code
|
|
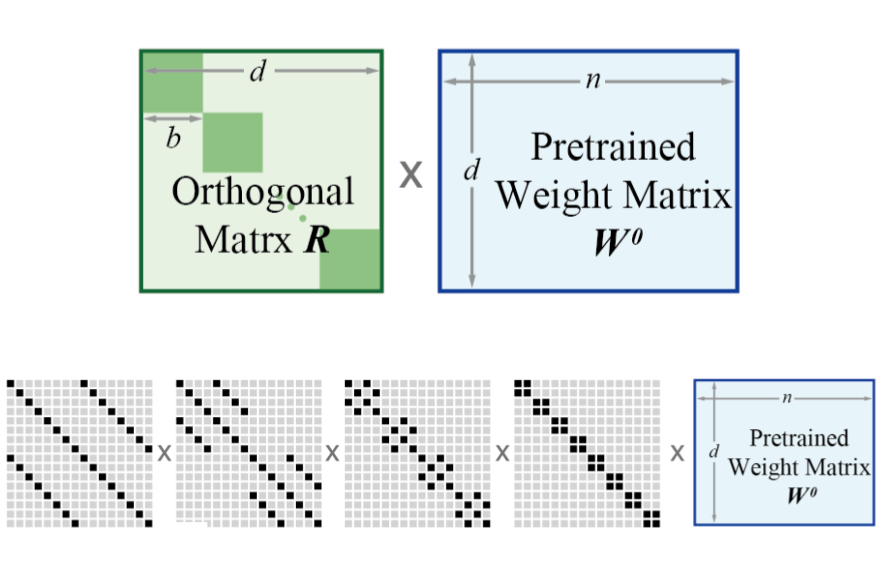
BOFT: Parameter-Efficient Orthogonal Finetuning via Butterfly Factorization
Weiyang Liu*, Zeju Qiu*, Yao Feng**, Yuliang Xiu**, Yuxuan Xue**, Longhui Yu**, Haiwen Feng, Zhen Liu, Juyeon Heo, Songyou Peng, Yandong Wen, Michael J. Black, Adrian Weller, Bernhard Schölkopf ICLR, 2024 project page / arXiv |
|
|
TECA: Text-Guided Generation and Editing of Compositional 3D Avatars
Hao Zhang*, Yao Feng*, Peter Kulits, Yandong Wen, Justus Thies, Michael J. Black 3DV, 2024 project page / arXiv / code |
|
|
DELTA: Learning Disentangled Avatars with Hybrid 3D Representations
Yao Feng, Weiyang Liu, Timo Bolkart, Jinlong Yang, Marc Pollefeys, Michael J. Black project page / arXiv / code |

|
MeshDiffusion: Score-based Generative 3D Mesh Modeling
Zhen Liu, Yao Feng, Michael J. Black, Derek Nowrouzezahrai, Liam Paull, Weiyang Liu ICLR, 2023 project page / arXiv / code |
|
|
SCARF: Capturing and Animation of Body and Clothing from Monocular Video
Yao Feng, Jinlong Yang, Marc Pollefeys Michael J. Black Timo Bolkart Siggraph Asia Conference, 2022 project page / arXiv / code |

|
PIXIE: Collaborative Regression of Expressive Bodies using Moderation
Yao Feng*, Vasileios Choutas*, Timo Bolkart, Dimitrios Tzionas, Michael J. Black 3DV, 2021 project page / paper / code |

|
DECA: Learning an Animatable Detailed 3D Face Model from In-The-Wild Images
Yao Feng*, Haiwen Feng*, Michael J. Black, Timo Bolkart SIGGRAPH, 2021 project page / arXiv / code |

|
PRNet: Joint 3D Face Reconstruction and Dense Alignment with Position Map Regression Network
Yao Feng, Fan Wu, Xiaohu Shao, Yanfeng Wang, Xi Zhou ECCV, 2018 project page / paper / code |
|
|