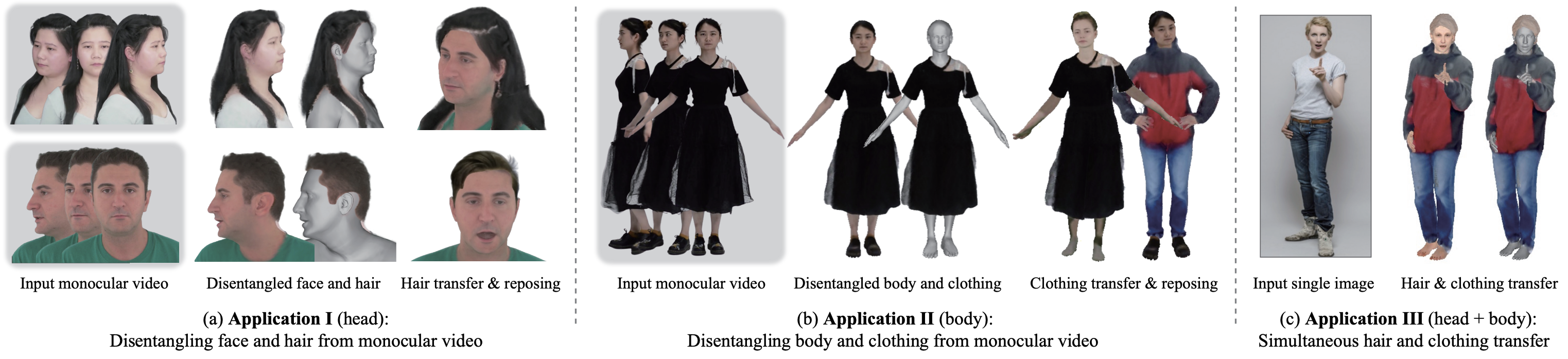
DELTA leans a compositional avatar using explicit Mesh and implicit NeRF represetntaions.
Tremendous efforts have been made to learn animatable and photorealistic human avatars. Towards this end, both explicit and implicit 3D representations are heavily studied for a holistic modeling and capture of the whole human (e.g., body, clothing, face and hair), but neither representation is an optimal choice in terms of representation efficacy since different parts of the human avatar have different modeling desiderata. For example, meshes are generally not suitable for modeling clothing and hair. Motivated by this, we present DisEntangLed AvaTArs (DELTA), which models humans with hybrid explicit-implicit 3D representations. DELTA takes a monocular RGB video as input, and produces a human avatar with separate body and clothing/hair layers. Specifically, we demonstrate two important applications for DELTA. For the first one, we consider the disentanglement of the human body and clothing and in the second, we disentangle the face and hair. To do so, DELTA represents the body or face with an explicit mesh-based parametric 3D model and the clothing or hair with an implicit neural radiance field. To make this possible, we design an end-to-end differentiable renderer that integrates meshes into volumetric rendering, enabling DELTA to learn directly from monocular videos without any 3D supervision. Finally, we show that how these two applications can be easily combined to model full-body avatars, such that the hair, face, body and clothing can be fully disentangled yet jointly rendered. Such a disentanglement enables hair and clothing transfer to arbitrary body shapes. We empirically validate the effectiveness of DELTA's disentanglement by demonstrating its promising performance on disentangled reconstruction, virtual clothing try-on and hairstyle transfer. To facilitate future research, we also release an open-sourced pipeline for the study of hybrid human avatar modeling.
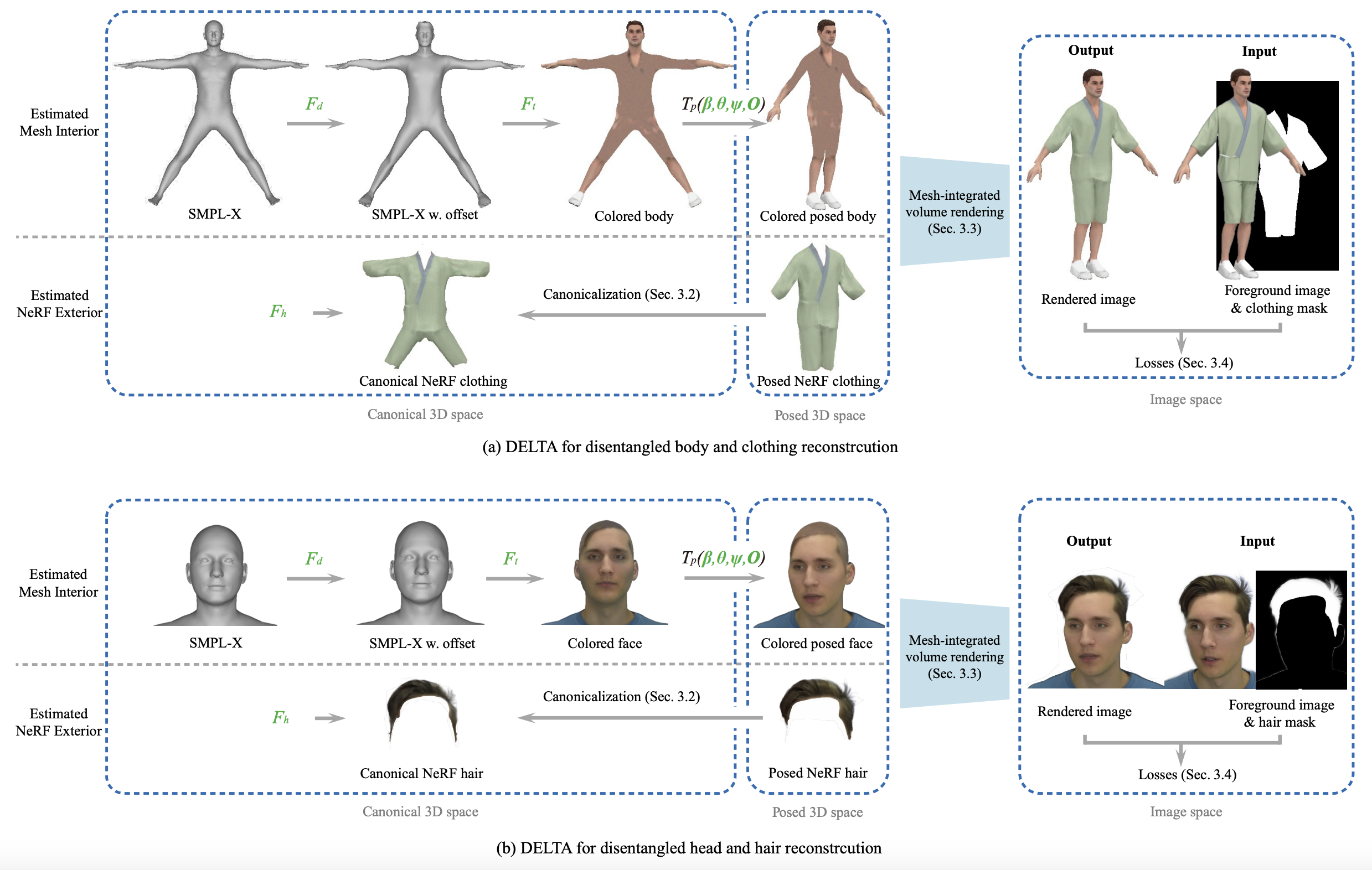
DELTA takes a monocular RGB video and clothing/hair segmentation masks as input, and outputs a human avatar with separate body and clothing/hair layers. Green letters indicate optimizable modules or parameters.
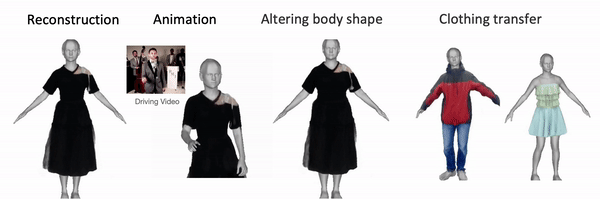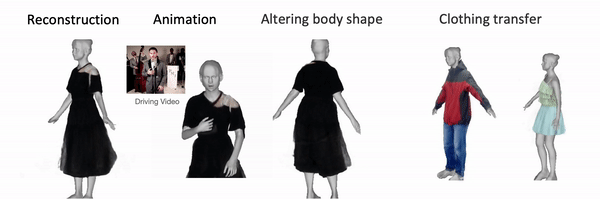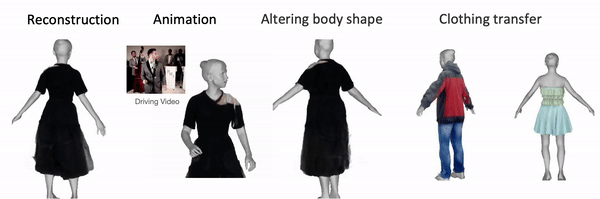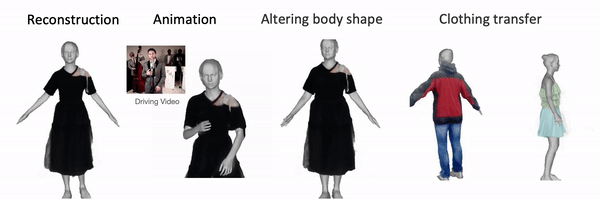
Once the avatar is learned by DELTA, we can animate it with control over face and hands. We can alter the body shape and the clothing/hair will adapt accordingly. We can also transfer the clothing/hairstyle learned from other videos to a new subject. Here we show the results of learning the body and clothing from a monocualr full body video. We capture the body and clothing as seperate layers, then animate the avatar with tracked body poses from PIXIE. We also show the clothing with different shapes, transfer clothing captured other videos (from iPER and SelfRecon ) to the subject.
Hairstyle Transfer: Given a monocular head video, we capture the avatar with disentagnled face and hair, we can transfer the hairstyles learned from other videos to it, resulting in the subject having different hairstyles.
Left: captured face and hair, middle: reference hairstyles (original videos from IMAvatar , Neural Head Avatar and NerFace ), right: subject with transferred hairstyle.
Clothing Transfer: Given any body shape, we can also transfer the clothing learned from other videos to it, resulting in the subject having different clothings.
Top: reference clothing (original videos from iPER, SelfRecon, Snapshot and SCARF , last example credits to Yao's Mom 😄 ), bottom: same subject with transferred clothing.
Simultanous Hair and Clothing Transfer: What's intriguing is our use of the SMPL-X body model for both the face and body, with the representations of hair and clothing learned in the same canonical space, even when sourced from different video examples. This streamlined approach enables effortless transfer of both hair and clothing to a new subject. Moreover, estimating a person's body shape from a single image has become remarkably straightforward. These elements converge to create an exciting demonstration: starting with a single RGB image, we can showcase how that individual would look with various hairstyles and outfits.
We can alter the body shape, the hair/clothing adapts accordingly.
We run marching cubes to extract the mesh from trained clothing/hair NeRF, and show it with the explicitly learned body mesh. Green indicates the mesh part extracted from NeRF-based clothing/hair.
We thank Sergey Prokudin, Yuliang Xiu, Songyou
Peng, Qianli Ma for fruitful discussions, and Peter Kulits, Zhen
Liu, Yandong Wen, Hongwei Yi, Xu Chen, Soubhik Sanyal, Omri
Ben-Dov, Shashank Tripathi for proofreading.
We also thank Betty Mohler, Sarah Danes, Natalia Marciniak, Tsvetelina Alexiadis, Claudia Gallatz, and Andres Camilo Mendoza Patino for their supports
with data. This work was partially supported by the Max Planck
ETH Center for Learning Systems.
Disclosure. MJB has received research gift funds from Adobe, Intel, Nvidia, Meta/Facebook, and Amazon. MJB has financial interests in Amazon, Datagen Technologies, and Meshcapade GmbH. While MJB is a part-time employee of Meshcapade, his research was performed solely at, and funded solely by, the Max Planck Society.
While TB is part-time employee of Amazon, this research was performed
solely at, and funded solely by, MPI.
@inproceedings{Feng2022scarf,
author = {Feng, Yao and Yang, Jinlong and Pollefeys, Marc and Black, Michael J. and Bolkart, Timo},
title = {Capturing and Animation of Body and Clothing from Monocular Video},
year = {2022},
booktitle = {SIGGRAPH Asia 2022 Conference Papers},
articleno = {45},
numpages = {9},
location = {Daegu, Republic of Korea},
series = {SA '22}
}
@article{Feng2023DELTA,
author = {Feng, Yao and Liu, Weiyang and Bolkart, Timo and Yang, Jinlong and Pollefeys, Marc and Black, Michael J.},
title = {Learning Disentangled Avatars with Hybrid 3D Representations},
journal={arXiv},
year = {2023}
}